

For larger evaluation jobs in Python we recommend using aevaluate(), the asynchronous version of evaluate(). It is still worthwhile to read this guide first, as the two have identical interfaces, before reading the how-to guide on running an evaluation asynchronously.In JS/TS evaluate() is already asynchronous so no separate method is needed.It is also important to configure the
max_concurrency/maxConcurrency arg when running large jobs. This parallelizes evaluation by effectively splitting the dataset across threads.Define an application
First we need an application to evaluate. Let’s create a simple toxicity classifier for this example.Create or select a dataset
We need a Dataset to evaluate our application on. Our dataset will contain labeled examples of toxic and non-toxic text.Requires
langsmith>=0.3.13Define an evaluator
You can also check out LangChain’s open source evaluation package openevals for common pre-built evaluators.
Requires
langsmith>=0.3.13Run the evaluation
We’ll use the evaluate() / aevaluate() methods to run the evaluation. The key arguments are:- a target function that takes an input dictionary and returns an output dictionary. The
example.inputsfield of each Example is what gets passed to the target function. In this case ourtoxicity_classifieris already set up to take in example inputs so we can use it directly. data- the name OR UUID of the LangSmith dataset to evaluate on, or an iterator of examplesevaluators- a list of evaluators to score the outputs of the function
Requires
langsmith>=0.3.13Explore the results
Each invocation ofevaluate() creates an Experiment which can be viewed in the LangSmith UI or queried via the SDK. Evaluation scores are stored against each actual output as feedback.
If you’ve annotated your code for tracing, you can open the trace of each row in a side panel view.
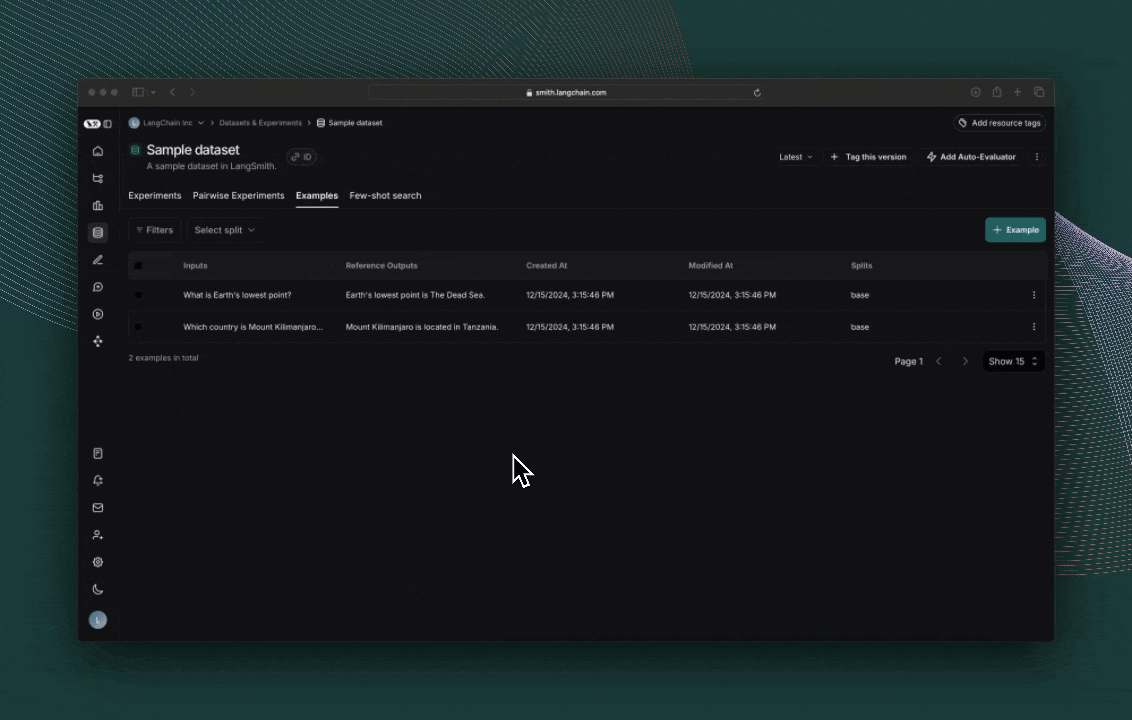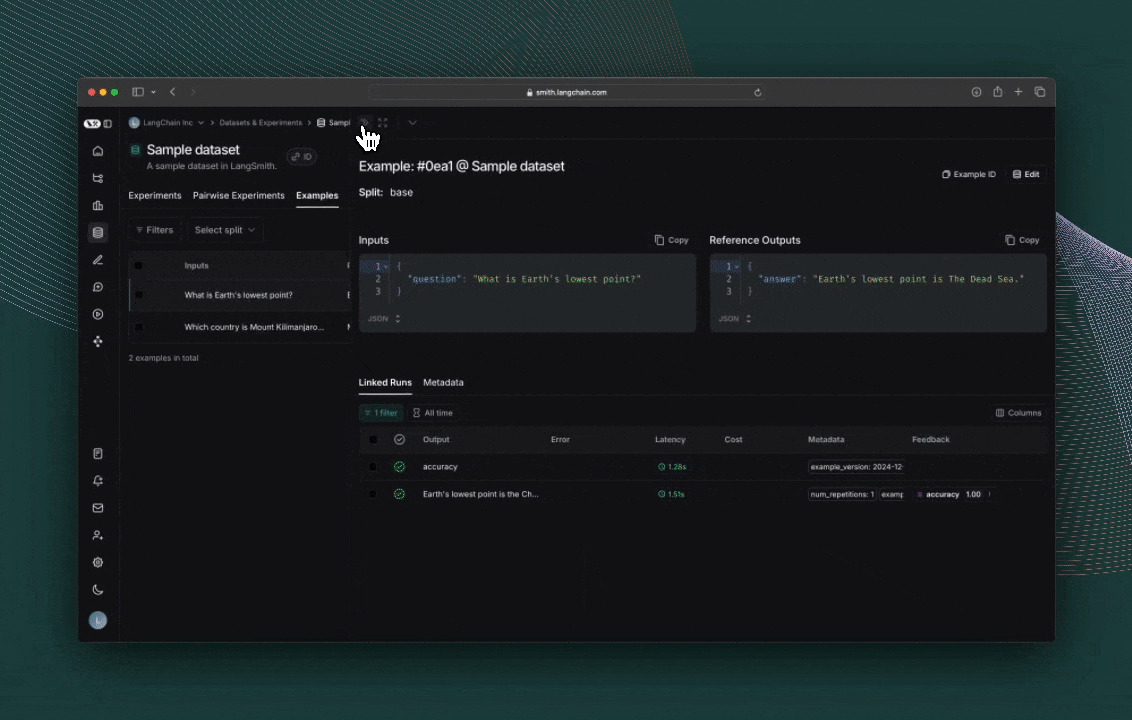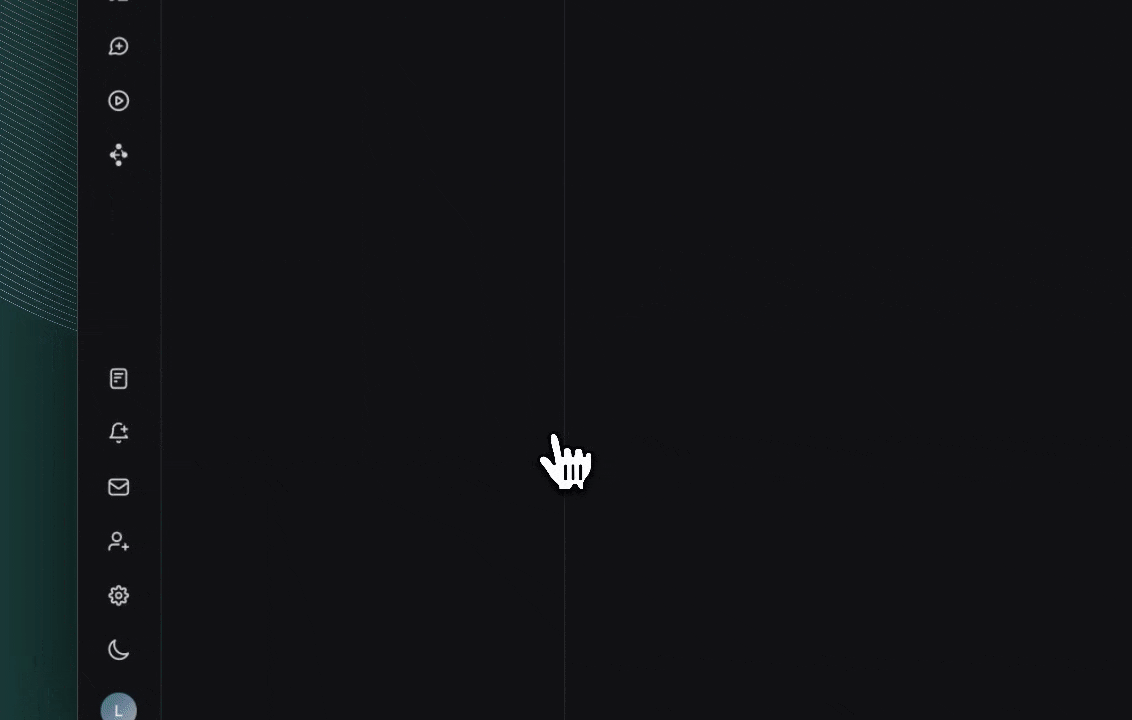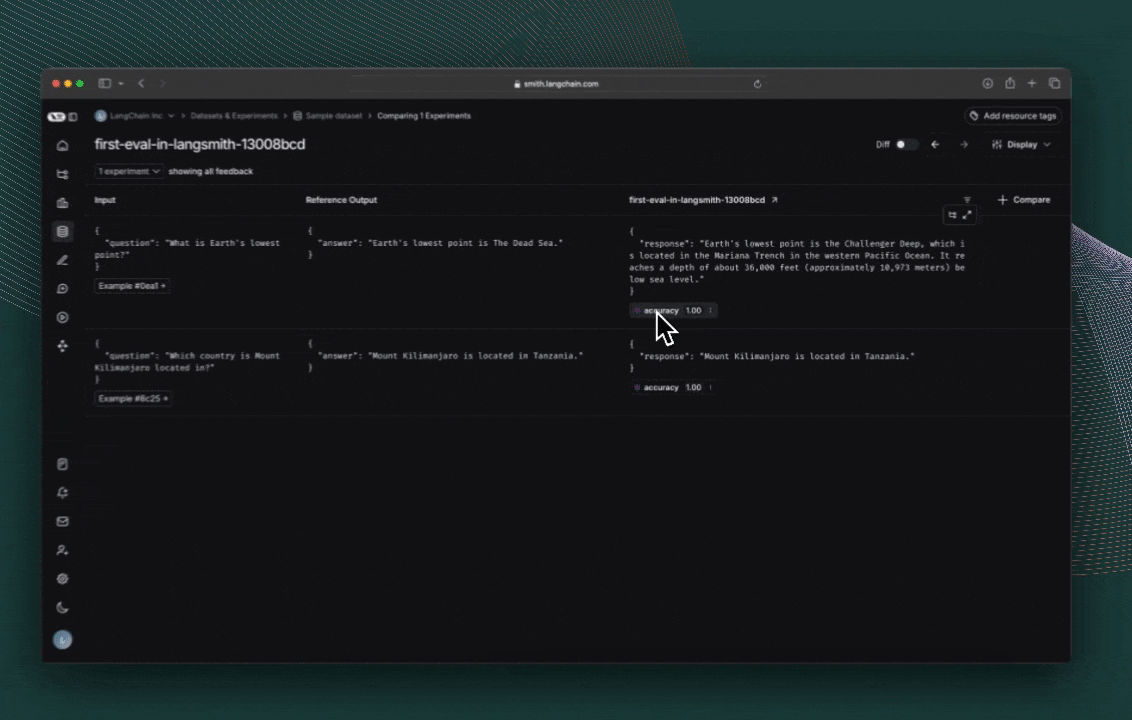
Reference code
Click to see a consolidated code snippet
Click to see a consolidated code snippet
Requires
langsmith>=0.3.13