

The objective
In this example, we will build a bot that classify GitHub issues based on their title. It will take in a title and classify it into one of many different classes. Then, we will start to collect user feedback and use that to shape how this classifier performs.Getting started
To get started, we will first set it up so that we send all traces to a specific project. We can do this by setting an environment variable:Set up automations
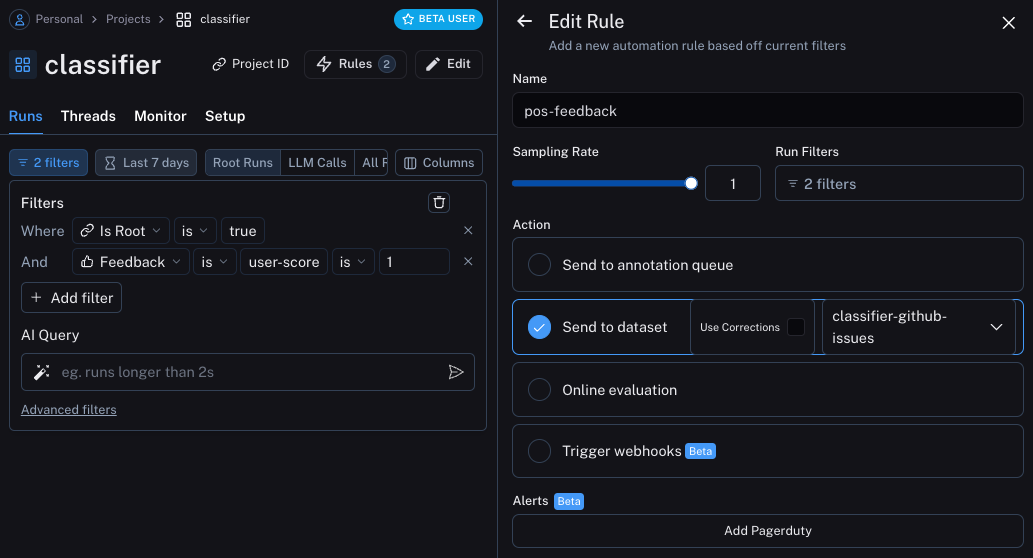
We can now set up automations to move examples with feedback of some form into a dataset. We will set up two automations, one for positive feedback and the other for negative feedback. The first will take all runs with positive feedback and automatically add them to a dataset. The logic behind this is that any run with positive feedback we can use as a good example in future iterations. Let’s create a dataset calledclassifier-github-issues to add this data to.
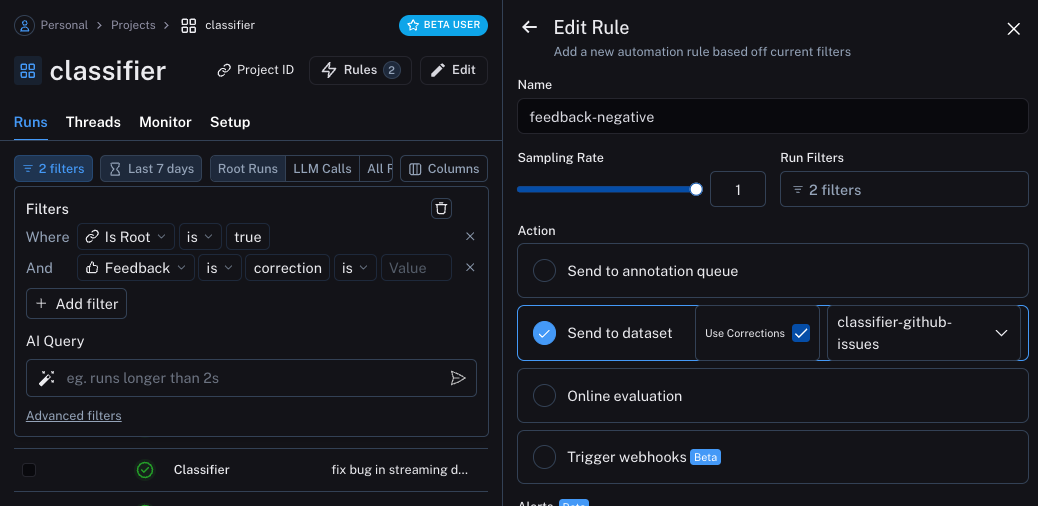
 The second will take all runs with a correction and use a webhook to add them to a dataset. When creating this webhook, we will select the option to “Use Corrections”. This option will make it so that when creating a dataset from a run, rather than using the output of the run as the gold-truth output of the datapoint, it will use the correction.
The second will take all runs with a correction and use a webhook to add them to a dataset. When creating this webhook, we will select the option to “Use Corrections”. This option will make it so that when creating a dataset from a run, rather than using the output of the run as the gold-truth output of the datapoint, it will use the correction.
Update the application
We can now update our code to pull down the dataset we are sending runs to. Once we pull it down, we can create a string with the examples in it. We can then put this string as part of the prompt!documentation
Semantic search over examples
One additional thing we can do is only use the most semantically similar examples. This is useful when you start to build up a lot of examples. In order to do this, we can first define an example to find thek most similar examples: