- Faster upload and download speeds due to more efficient binary file transfers
- Enhanced visualization of different file types in the LangSmith UI
SDK
1. Create examples with attachments
To upload examples with attachments using the SDK, use the create_examples / update_examples Python methods or the uploadExamplesMultipart / updateExamplesMultipart TypeScript methods.- Python
- TypeScript
Requires
langsmith>=0.3.13Along with being passed in as bytes, attachments can be specified as paths to local files. To do so pass in a path for the attachment
data value and specify arg dangerously_allow_filesystem=True:2. Run evaluations
Define a target function
Now that we have a dataset that includes examples with attachments, we can define a target function to run over these examples. The following example simply uses OpenAI’s GPT-4o model to answer questions about an image and an audio clip.- Python
- TypeScript
The target function you are evaluating must have two positional arguments in order to consume the attachments associated with the example, the first must be called
inputs and the second must be called attachments.- The
inputsargument is a dictionary that contains the input data for the example, excluding the attachments. - The
attachmentsargument is a dictionary that maps the attachment name to a dictionary containing a presigned url, mime_type, and a reader of the bytes content of the file. You can use either the presigned url or the reader to get the file contents. Each value in the attachments dictionary is a dictionary with the following structure:
Define custom evaluators
The exact same rules apply as above to determine whether the evaluator should receive attachments. The evaluator below uses an LLM to judge if the reasoning and the answer are consistent. To learn more about how to define llm-based evaluators, please see this guide.- Python
- TypeScript
Update examples with attachments
In the code above, we showed how to add examples with attachments to a dataset. It is also possible to update these same examples using the SDK. As with existing examples, datasets are versioned when you update them with attachments. Therefore, you can navigate to the dataset version history to see the changes made to each example. To learn more, please see this guide. When updating an example with attachments, you can update attachments in a few different ways:- Pass in new attachments
- Rename existing attachments
- Delete existing attachments
- Any existing attachments that are not explicitly renamed or retained will be deleted.
- An error will be raised if you pass in a non-existent attachment name to
retainorrename. - New attachments take precedence over existing attachments in case the same attachment name appears in the
attachmentsandattachment_operationsfields.
- Python
- TypeScript
UI
1. Create examples with attachments
You can add examples with attachments to a dataset in a few different ways.From existing runs
When adding runs to a LangSmith dataset, attachments can be selectively propagated from the source run to the destination example. To learn more, please see this guide.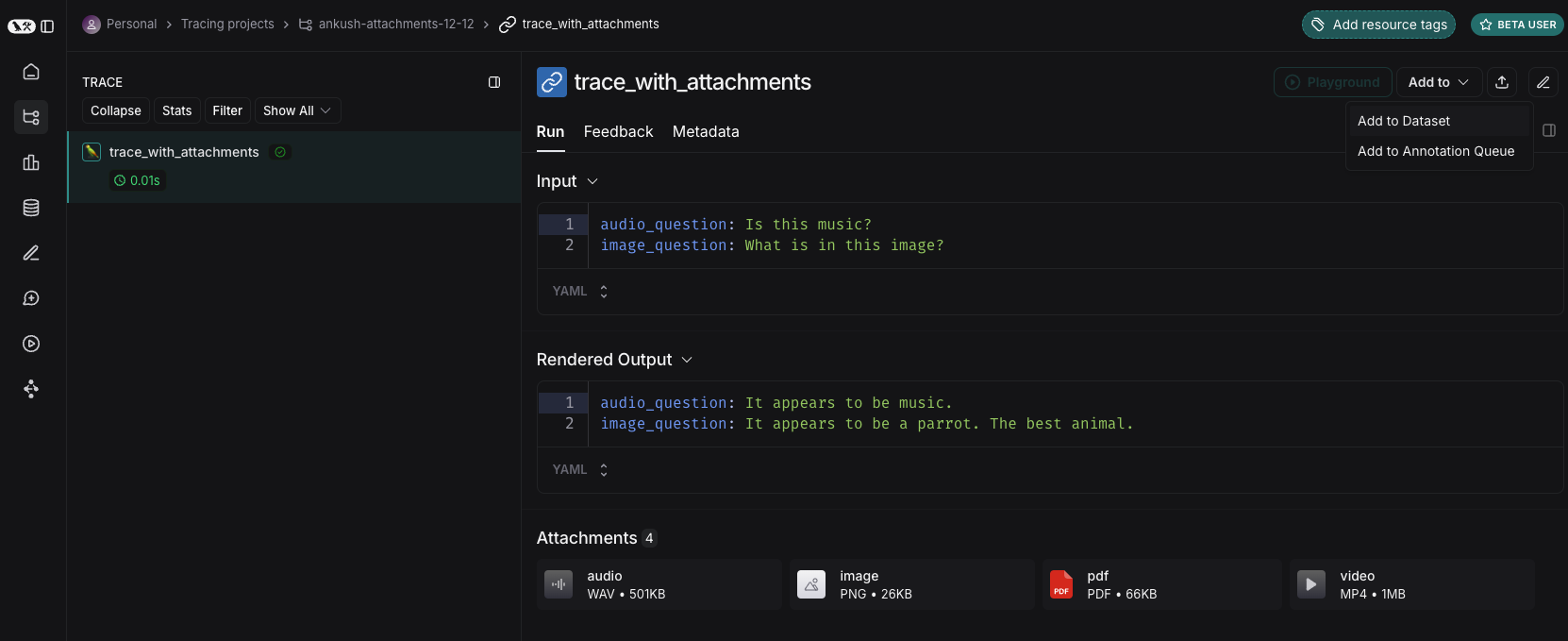
From scratch
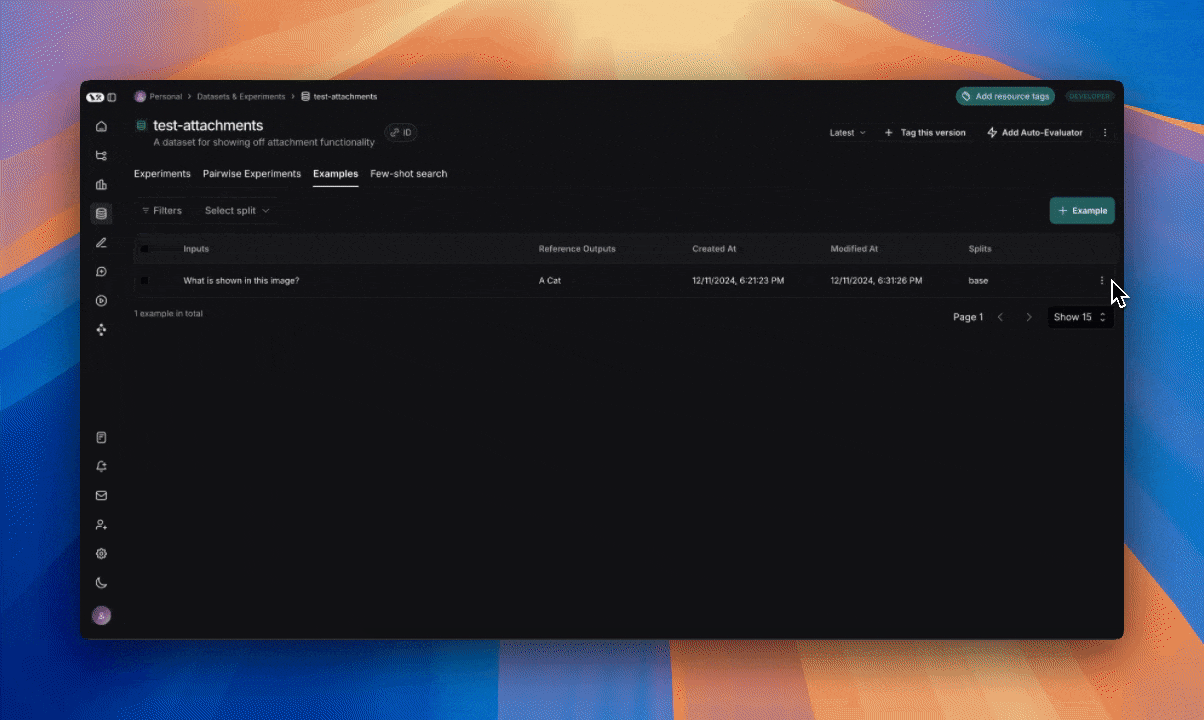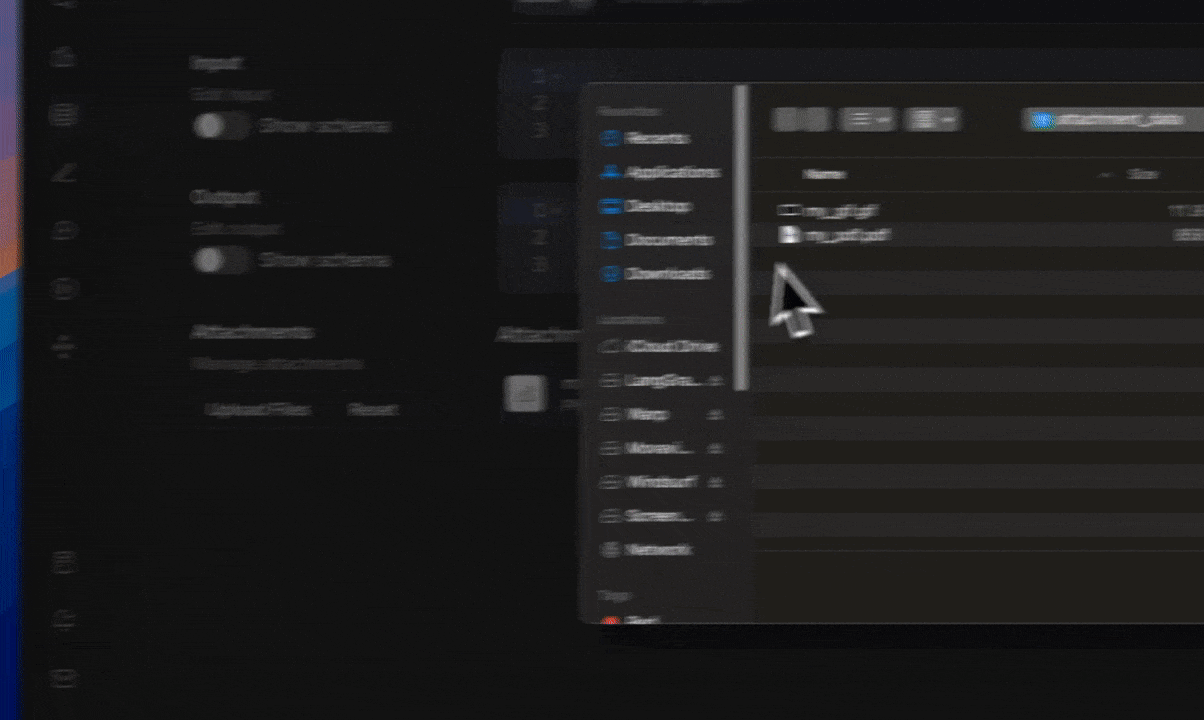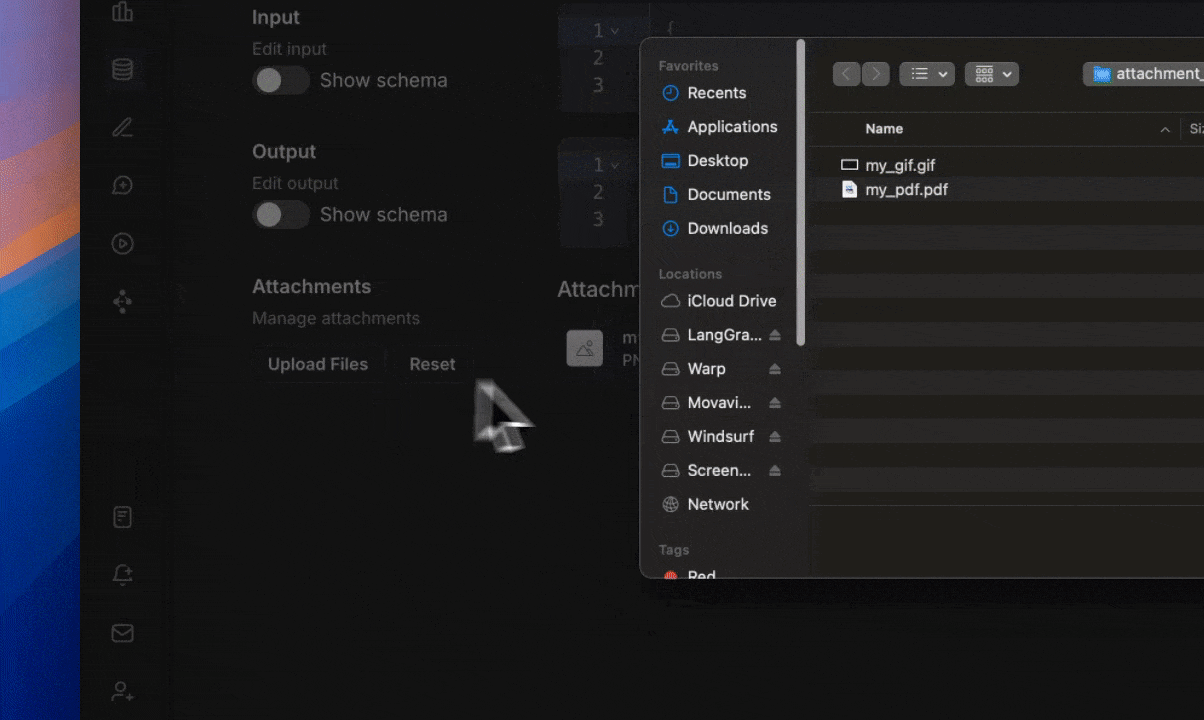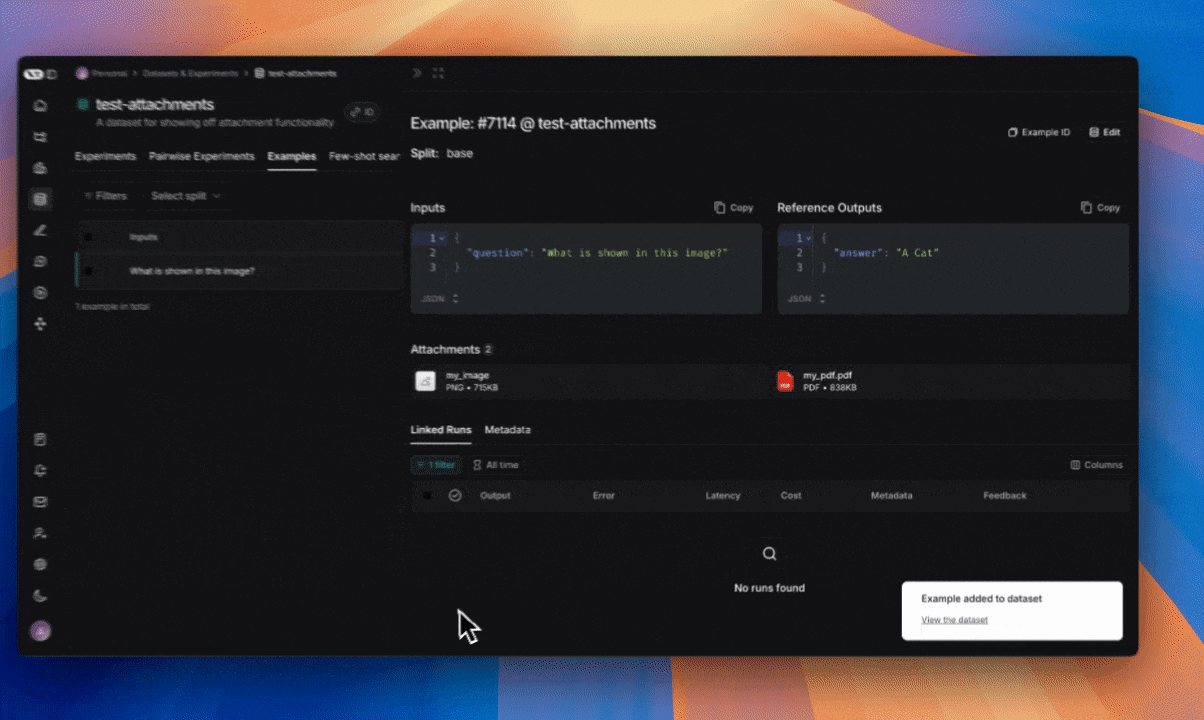
You can create examples with attachments directly from the LangSmith UI. Click the+ Example button in the Examples tab of the dataset UI. Then upload attachments using the “Upload Files” button:
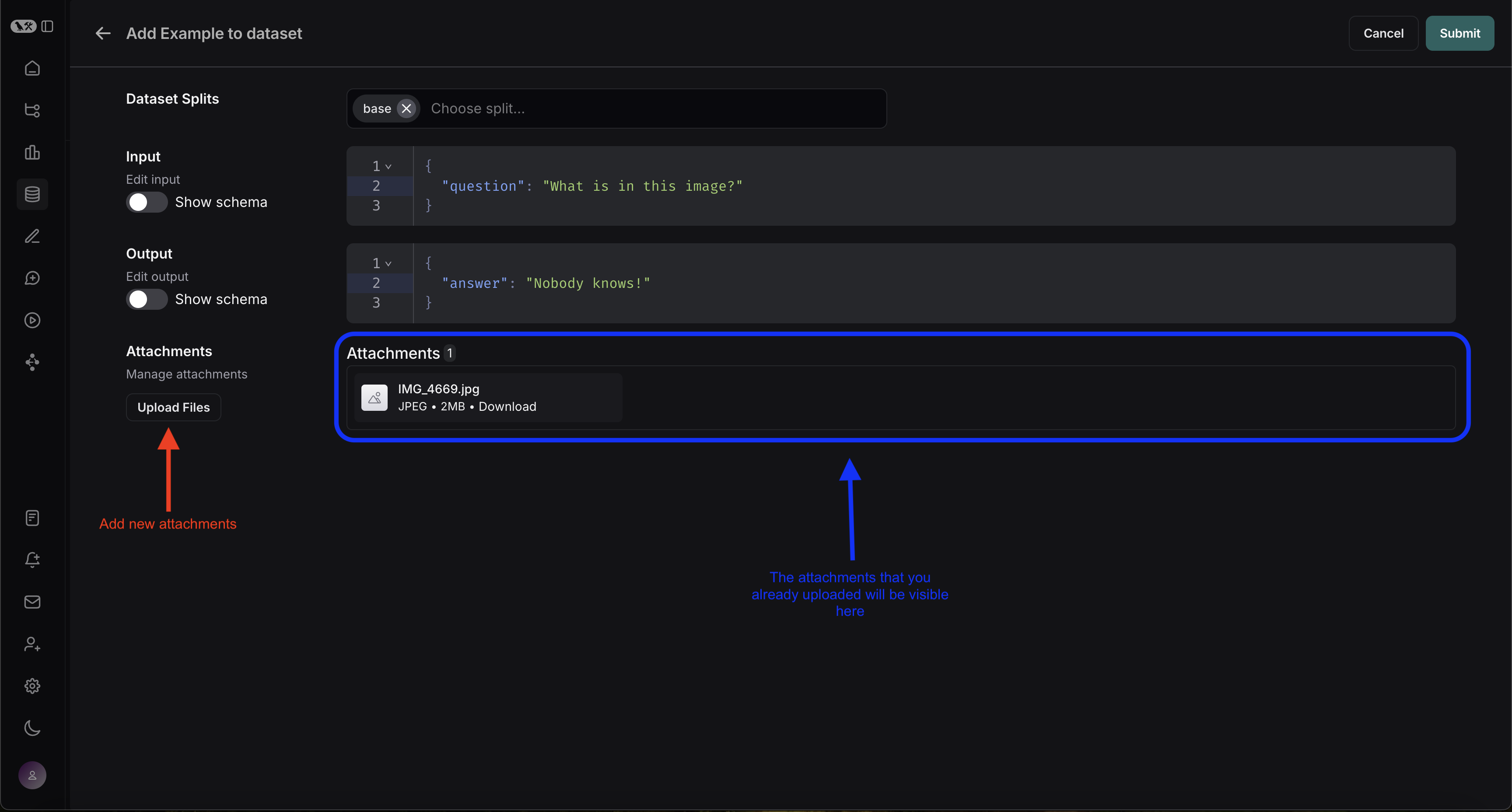
2. Create a multimodal prompt
The LangSmith UI allows you to include attachments in your prompts when evaluating multimodal models: First, click the file icon in the message where you want to add multimodal content. Next, add a template variable for the attachment(s) you want to include for each example.- For a single attachment type: Use the suggested variable name. Note: all examples must have an attachment with this name.
- For multiple attachments or if your attachments have varying names from one example to another: Use the
All attachmentsvariable to include all available attachments for each example.
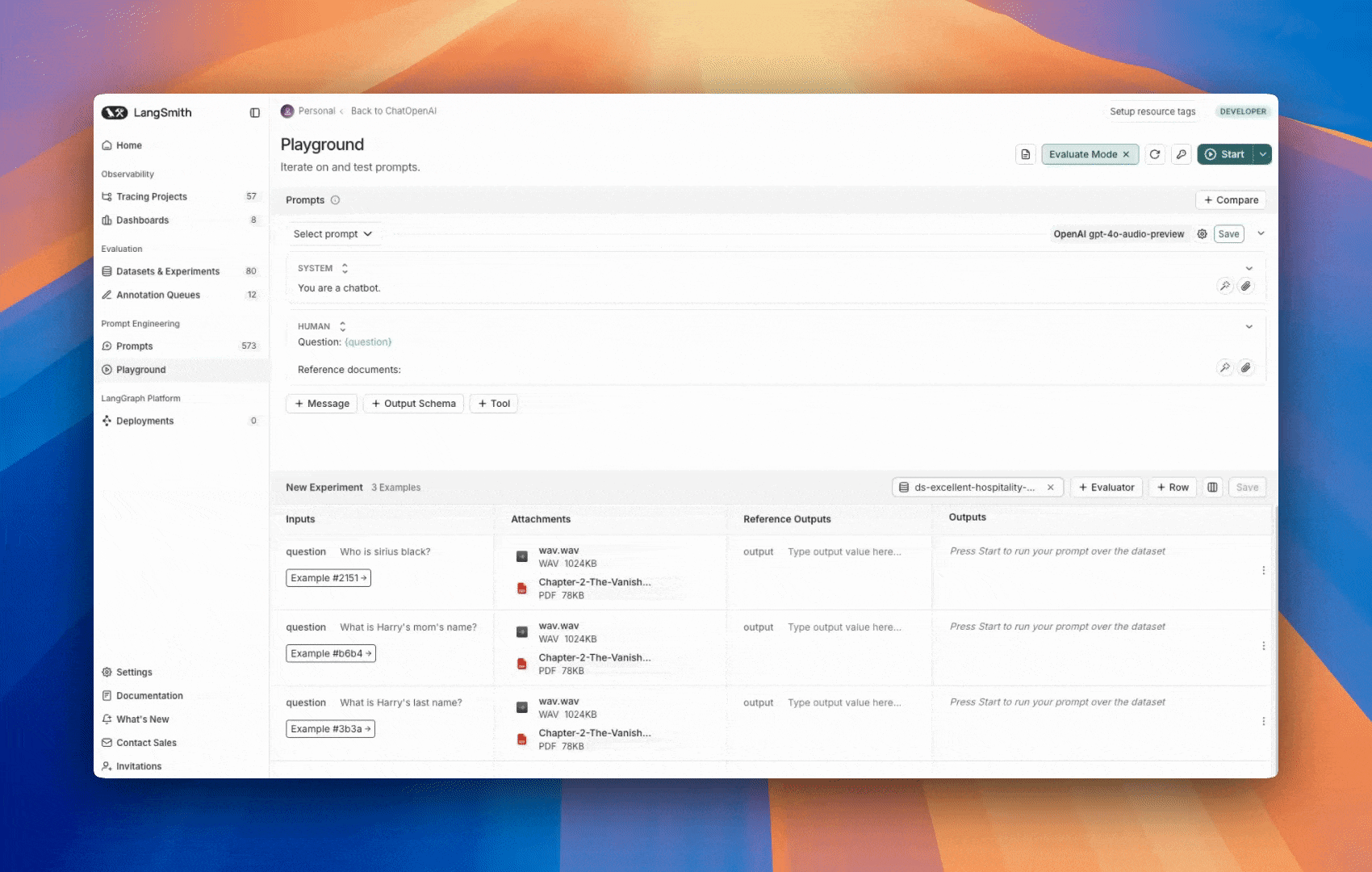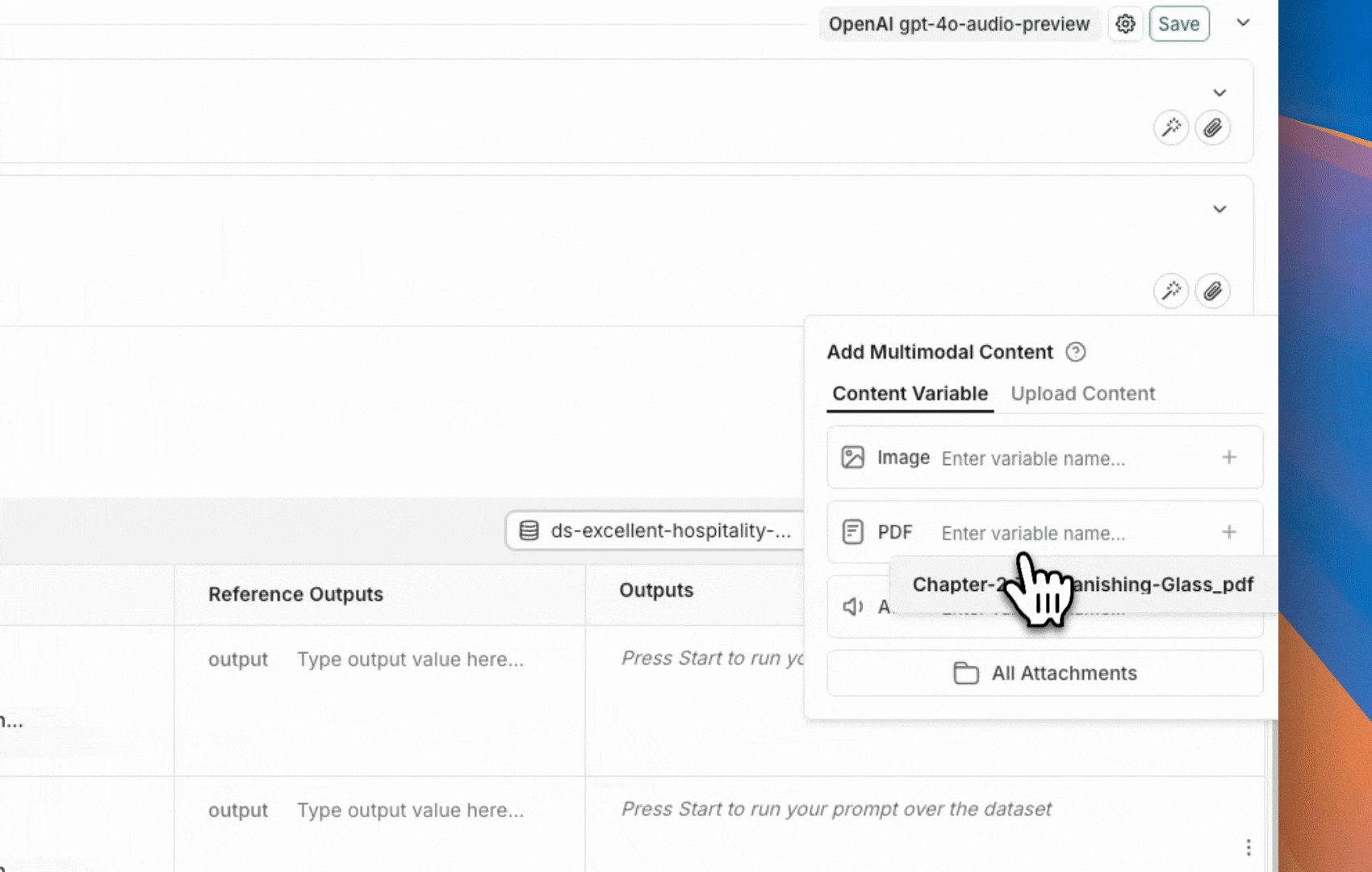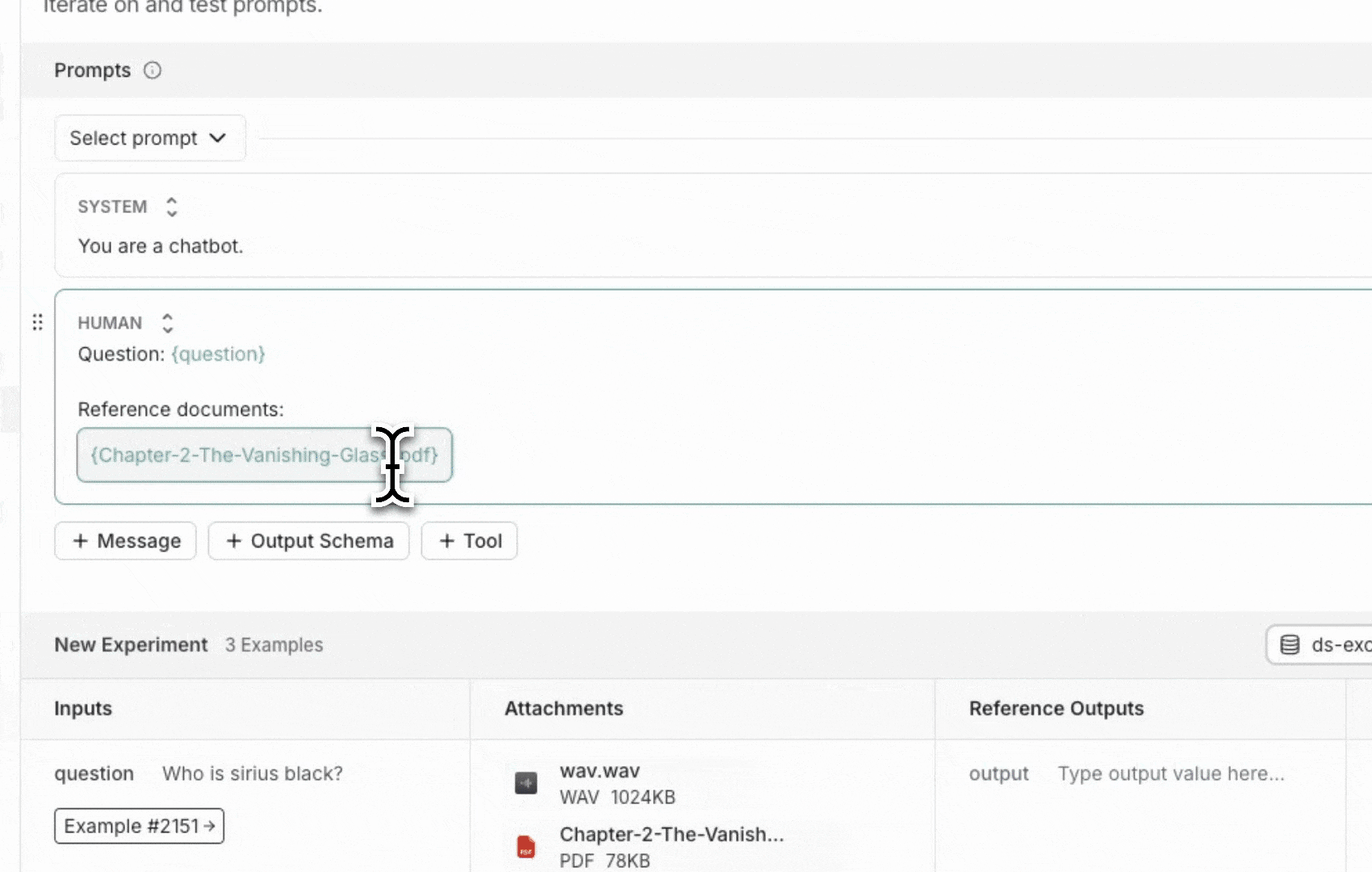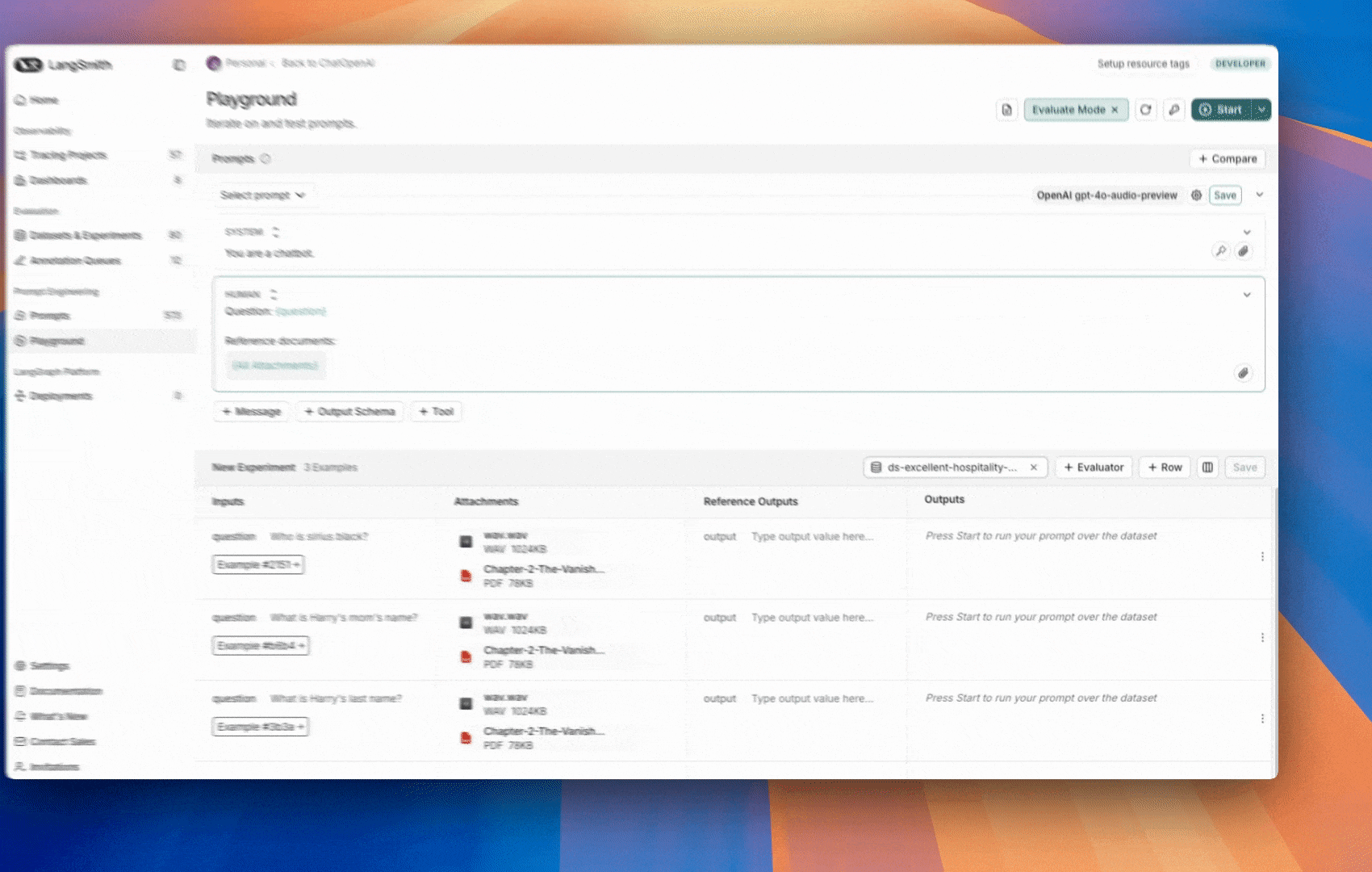
Define custom evaluators
The LangSmith playground does not currently support pulling multimodal content into evaluators. If this would be helpful for your use case, please let us know in the LangChain Forum (sign up here if you’re not already a member)!
- OCR → text correction: Use a vision model to extract text from a document, then evaluate the accuracy of the extracted output.
- Speech-to-text → transcription quality: Use a voice model to transcribe audio to text, then evaluate the transcription against your reference.
Update examples with attachments
Attachments are limited to 20MB in size in the UI.
- Upload new attachments
- Rename and delete attachments
- Reset attachments to their previous state using the quick reset button